Software Architecture Document
Table of Contents
- Introduction
- Architectural Representation
- Architectural Goals and Constraints
- Use-Case View
- Logical View
- Process View
- Deployment View
- Implementation View
- Data View
- Size and Performance
- Quality
- Tools
1. Introduction
1.1 Purpose
This document provides a comprehensive architectural overview of the system, using a number of different architectural views to depict different aspects of the system. It is intended to capture and convey the significant architectural decisions which have been made on the system.
1.2 Scope
This document describes the technical architecture of the Betterzon project, including the structure of classes, modules and dependencies.
1.3 Definitions, Acronyms and Abbreviations
| Abbrevation | Description |
|---|---|
| API | Application programming interface |
| REST | Representational state transfer |
| SRS | Software Requirements Specification |
| UC | Use Case |
| VCS | Version Control System |
| n/a | not applicable |
1.4 References
| Title | Date | Publishing organization |
|---|---|---|
| Betterzon | 2020-12-06 | Betterzon |
| Repository on GitHub | 2020-12-06 | Betterzon |
| Documentation | 2020-12-06 | Betterzon |
| UC Search for Product | 2020-12-06 | Betterzon |
| UC Price Alarm List | 2020-12-06 | Betterzon |
| UC Web Crawler | 2020-12-06 | Betterzon |
| UC Manage Vendor Shop | 2020-12-06 | Betterzon |
| UC Favorite Shop List | 2020-12-06 | Betterzon |
| UC Add new products | 2020-04-17 | Betterzon |
| UC Page administration | 2020-04-17 | Betterzon |
| SRS | 2020-12-06 | Betterzon |
1.5 Overview
This document contains the Architectural Representation, Goals and Constraints as well as the Logical, Deployment, Implementation and Data Views.
2. Architectural Representation
2.1 Tech Stack

2.2 Class Diagram
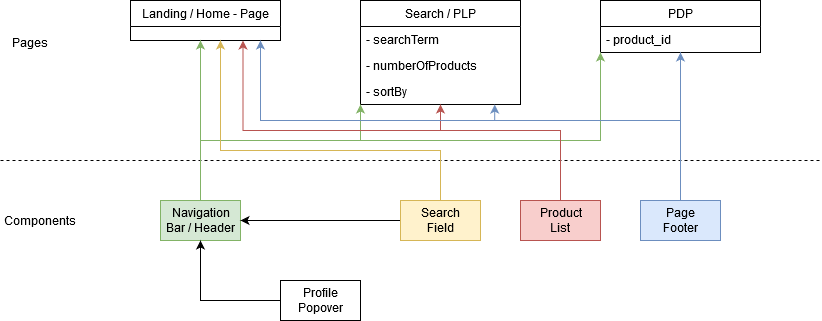
As we use ExpressJS in the backend and Angular in the frontend, we don't have any real classes. However, for a clearer structure, the frontend is divided into two types of Angular components, "components" and "pages". The following diagram shows how these are connected.
3. Architectural Goals and Constraints
The Frontend and the Backend are split up into different components. The web crawler which will be developed later will be an independent component as well. This ensures maximum maintainability and the option to switch one of these components to a different technology in the future without having to rewrite the whole application.
Patterns
One of the most important patterns we are using is the Observable / Subscriber Pattern in Angular. This is used to make asynchronous API requests without having the application waiting for the answer and hence blocking the user from doing something different in the meantime. To maintain a clear code structure, we are also using the proxy pattern to extend existing interfaces in TypeScript.
Database
For the Database we use mariaDB as we already have multiple mariaDB servers up and running which we can use, which saves time because we don't have to set up a new server.
Backend
For the Backend we use a Node.js Server with ExpressJS. These are used to create a RESTful API in TypeScript.
Frontend
We use Angular to create a single-page application. This application will connect to our RESTful API.
4. Use-Case View

5. Logical View
Backend
The Backend is split into the different API endpoints, allowing for easy understanding. For every endpoint, there is a router class, a service class and some interfaces. The router class handles the incoming requests and sends the responses and the service class is used for accessing the database and performing other checks, such as authorization.
Frontend
The components in the frontend are divided into "pages" and "components" with pages being the angular components that build a whole page and components being small template components that can be used on different pages when needed.
6. Process View
- When the user opens our page, the angular application is downloaded to the user's computer. By clicking through the pages, the application performs HTTP requests to our backend to load the required data.
- If the user wants to add another product, the backend performs a callout to one of our crawling instances, causing it to fetch the required product details.
- The nightly crawling process is centrally triggered from one crawler load balancing instance. This instance sends requests to the normal crawler instances, distributing the crawling tasks across all available instances.
7. Deployment View

9. Data View

10. Size and Performance
The service runs distributed on two smaller vServers, so the performance will be anti-proportional to the amount of users. Given however that this is a smaller platform with an expected user count not exceeding 1000 per day, there shouldn't arise any performance difficulties.
11. Quality/Metrics
We use Jenkins as CI/CD server. Our Jenkins instance fullfills two purposes:
- Every commit is automatically built by Jenkins. The build status is then sent back to GitHub. That way, we can easily see if a commit contains changes that brake the application and fix them before we merge a pull request.
- Once we merge a pull request to master, the project gets built and deployed to our Webserver by Jenkins automatically
This way, we can assure that no breaking changes are deployed which would result in a website downtime.
12. Tools
We use the following tools for the development